簡單了解前導知識後就是正式進入機器學習的幾種模式>>
1.Supervised Learning:Training data with output labels.
訓練機器學習時提供正確答案,依照輸出的資料類型分為兩種:
Classification: output labels are categories values.
Regression: output labels are numeric values.
2.Unsupervised Learning:Training data without output labels.
不提供正確答案,將資料進行分組:Clustering (grouping similar instances).
3.Reinforcement Learning:Training algorithms receive no supervised output labels but use delayed reward and punishment to learn best actions.
不提供正確解答,但是將依照成果給予獎勵或懲罰,以此來讓機器學習。
表格化介紹以上三種學習模式: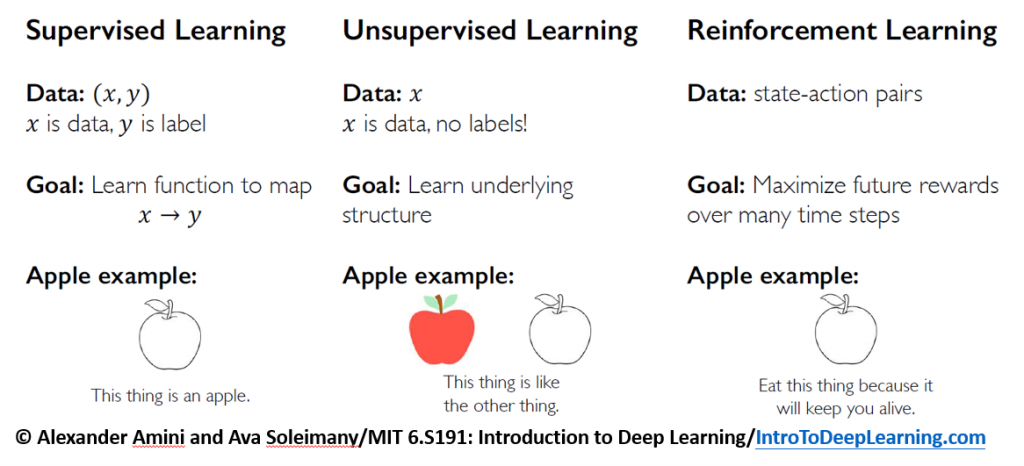
組成機器學習的元素:輸入、輸出、目標函式、資料、假設(Hypothesis)
舉例來說,如果要利用收入和儲蓄的數據來看是否核發信用卡的話:
輸入:收入、儲蓄 X[x1,x2]
輸出:是/否 (y)
目標函式:f(X)=y
資料:以前的數據(X1,y1)、(X2,y2)...(Xn,yn)
假設函式:g(X)=y
機器學習的目的是找到假設的函式使它趨近於未知的目標函式,
於是先以現有的資料代入演算法A,得出假設的函式後再預測輸入值H的輸出為何。
可以得知組成一個學習模型的兩個要素:完成學習的演算法A和待預測的輸入值H。
學習模型也分為訓練階段和測試階段: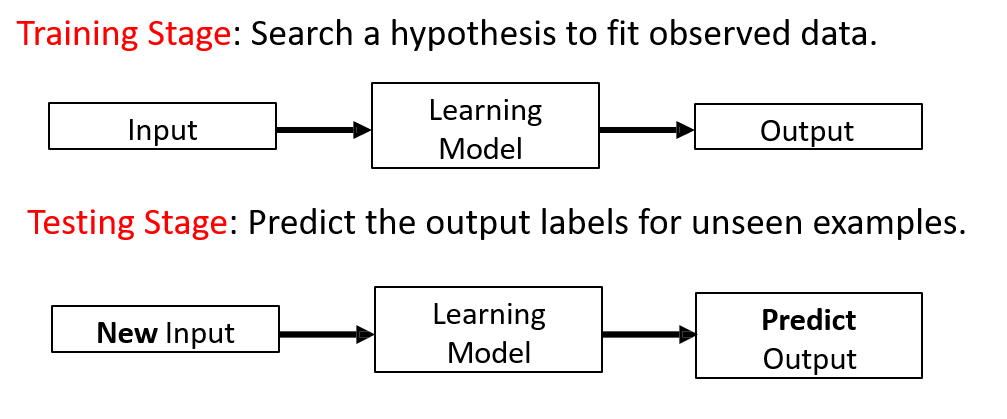
學習模型因為演算法的不同所以可以分為很多種,介紹三個較為常見的Model類別:
1.Linear Model,演算法:如PLA (線性分類)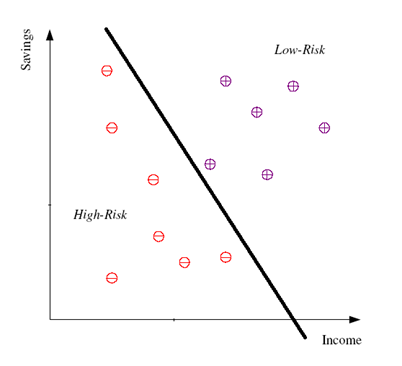
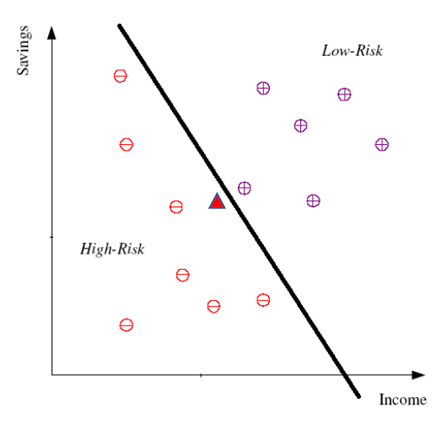
2.Rule-Based Model ,演算法:如ID3 (有規則可循)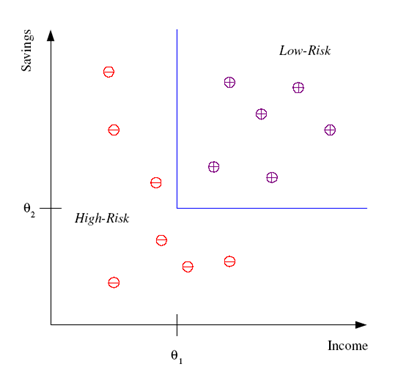
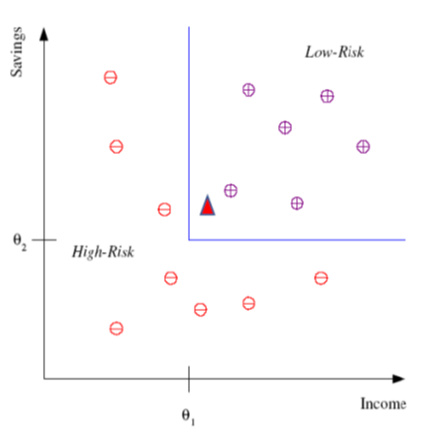
3.Instance-Based Model,演算法:如1NN (看鄰居答案之後照抄)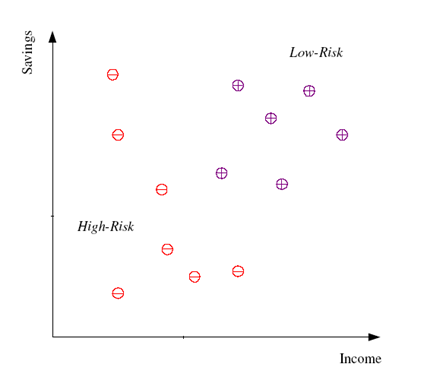
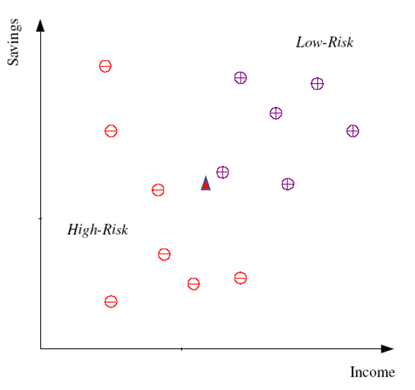
注意:在查詢之前資料會一直放在序列中等待,是一個懶惰的演算法
 minimindy
minimindy

 iThome鐵人賽
iThome鐵人賽